今年1年いろいろ調べた際に参照した、AWSにおける分散システムの可用性設計、特に AZ を活用した耐障害性設計に関する公式資料・参考記事をまとめました。
- 1. Whitepaper
- 2 Builder's Library, Blog
- 3. re:Inventセッション
- 4. Application Recovery Controller (ARC)
- 5. その他参考
1. Whitepaper
Well-Architected フレームワーク - 信頼性の柱
- REL 10: ワークロードを保護するための障害分離
- REL 11: コンポーネントの障害に耐えるワークロード設計
マルチAZの高度なレジリエンスパターン
- Introduction
- マルチAZは二元的な障害イベントの際にはうまく機能するが、Gray Failureに直面すると問題が発生することがある
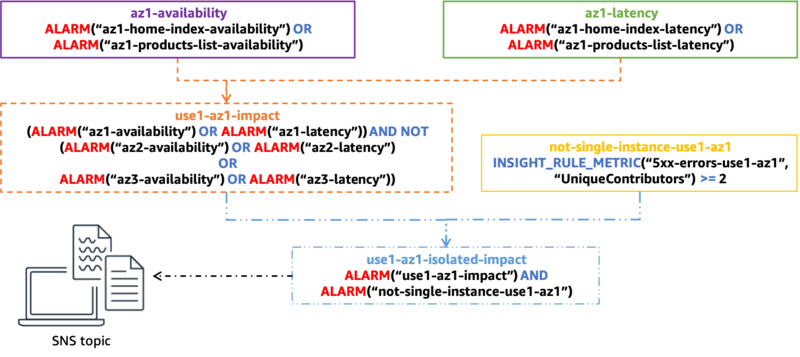
- 単一のAZに限定されたグレー障害の影響を検出するためにワークロードを計測する方法と、そのAZでの影響を軽減するための対策について指針を提供
- ⚠️このようなタイプのワークロードは、全体のポートフォリオの中で小さな部分を占める可能性が高いため、このガイダンスはプラットフォームレベルではなく、ワークロードレベルで検討されるべきです
- Gray Failures
- グレー障害の定義と特徴
- グレー障害の例
- マルチAZシステムでの影響:特定のAZとデータベース間の接続に問題が発生する場合がある
- 各サービスのヘルスチェックやステータスでは正常と判断するが、ワークロードは可用性に影響を受ける
- グレー障害への対応
- 3つの選択肢:何もしない、影響を受けたAZを退避、別のリージョンにフェイルオーバー
- 大多数のワークロードは何もしないで問題ない
- 3つの選択肢:何もしない、影響を受けたAZを退避、別のリージョンにフェイルオーバー
- AZ退避の利点
- より低いRTO(Recovery Time Objective):インフラとリソースが既に複数のAZにプロビジョニングされている
- より低いRPO(Recovery Point Objective):多くのAWSサービスが単一リージョン内で強力なデータ永続性を提供
- AZ退避は静的に可能
- リージョナルサービスはAZ退避では対応ができない
- Multi-AZ Observability
- インストルメンテーションの重要性
- CloudWatch 複合アラームによる障害検出
- AZ Evacuation Patteerns
- 達成すべき成果
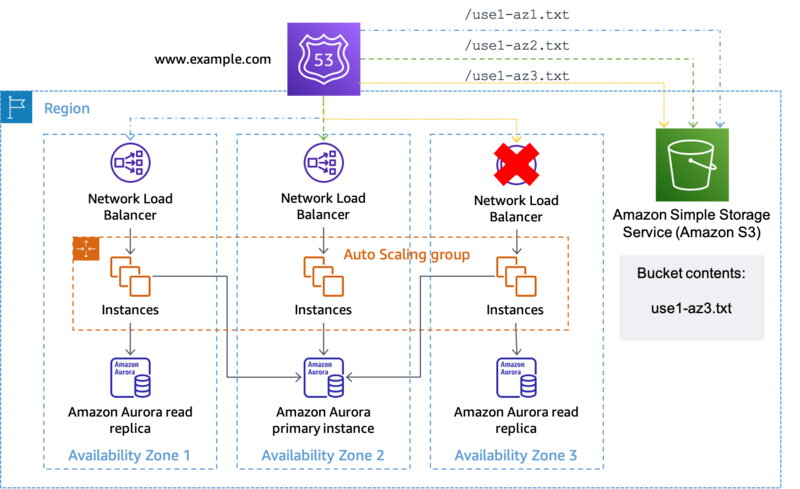
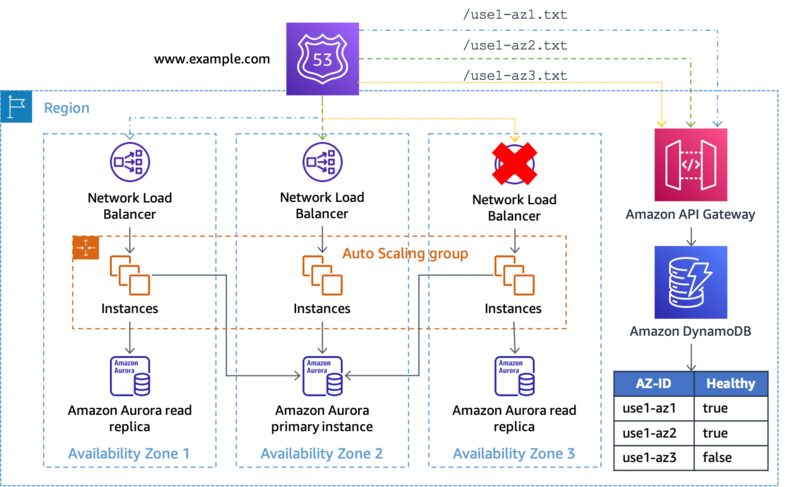
- 1/影響を受けているAZへの作業の送信を停止する(AZIを実装する)
- 影響を受けていないAZのリソースが、影響を受けているAZのリソースと相互作用しないようにする
- 2/影響を受けているAZに新しいキャパシティがプロビジョニングされないようにする
- 1/影響を受けているAZへの作業の送信を停止する(AZIを実装する)
- AZ Independence (AZI)
- AZI退避はデータプレーン動作をなるべく使う
- 達成すべき成果
分散システムにおける高可用性設計
- ※この記事は古い
- Understanding availability
- 耐障害性(Fault Trelant)と障害分離(Fault Isolation)
- 耐障害性:サブシステムの障害に耐え、可用性を維持する能力(確立されたSLA内で正しいことを行う)
- 障害分離:障害が発生した際の影響範囲を最小限に抑える。れは通常、モジュール化によって実装される。独立して故障し修復可能。モジュールを超えて伝搬しない。
- コントロールプレーン、データプレーン、静的安定性のアーキテクチャパターン
- 可用性の計測
- 制御できるのは、障害をどれだけ早く検知し、対処するか。つまりMTTDとMTTRの削減

セルベースアーキテクチャ
- Introduction
- What is a cell-based architecture?
- Why use a cell-based architecture?
- When to use a cell-based architecture?
実装はこちらの解説がわかりやすい
https://pages.awscloud.com/rs/112-TZM-766/images/AWS-58_Architecture_AWS_Summit_JP_2024.pdfpages.awscloud.com
- 1/ テスト不足、2/ オペミス、3/ Poison pillに対して影響範囲を狭めるアプローチとしてセルベースアーキテクチャを提案している
- 本来はテストや切り戻し、アプリ実装の工夫等で対応を行うべきだが、すべてを想定することは難しいため
- セルベースアーキテクチャのメリット
- 障害分離性
- スケール性
- テスト性
セルベースアーキテクチャ事例
- AWS re:Invent 2021 - Unlocking scalability with cells: New Relic’s journey to AWS - YouTube
- AWS re:Invent 2022 - Journey to cell-based microservices architecture on AWS for hyperscale (ARC312) - YouTube
- An Insider Look: How Okta Builds and Runs Scalable Infrastructure | Okta
- Slack’s Migration to a Cellular Architecture | Engineering at Slack
- re:Invent 2024: AWSとSlackが語るCell-based Architectureの実践
- Egressプラットフォームのセルベース化
- 信頼性の向上、コストが目的
- Slack全体として、重要なサービスをAZ Affinityアーキテクチャパターンに移行する大規模な取り組みが進行中
- Egressスタックの運用コストが予算のガイドラインをはるかに上回るペースで増加し続けていたため、 このコスト問題に対処する必要
- Affinityのアーキテクチャパターン
- 問題のBlast Radiusを単一のAvailability Zone内に限定すること
- 必要に応じてAZを退避できる能力を持つこと
- 一度リクエストがAZに入ったら、そのすべてのダウンストリーム依存関係が同じAZ内に存在しなければならない
- re:Invent 2024: Stripeが実現する99.9995%の可用性 - 技術と文化
- Stripeは金融インフラとして99.9995%(5.5ナイン)の可用性を目指している
- 月に13秒のダウンタイムしか許容されない厳しい基準を設定している
- 信頼性と可用性の技術的な側面
- グレー障害への対応
- 異常検知を利用
- 他のノードと比較して異常な動作をしているノードを自動的に発見
- カオステスティングとフォールトインジェクション
- サービスが成熟するにつれて、より多くの障害を有効にしていき、QA環境では常にシステムを稼働させていく
- 負荷テスト
- 継続的デリバリー
- 信頼性文化の構築
- Stripeは金融インフラとして99.9995%(5.5ナイン)の可用性を目指している
- re:Invent 2024: AWSとCapital Oneが語るレジリエントなアプリ構築
- Capital Oneの2つのミッションクリティカルなプラットフォームにおけるCell-based Architectureの実装事例
- オーソリプラットフォーム(Zonal Independence Cell)
- Core Banking Platform(Regional Cell-based)
- 複数テナント(リテール顧客、カード顧客等)の異なる要件に対応するためテナントセグメンテーションを重視
- Siloed方式とPooled方式の両方をサポートし、Noisy neighbor effectを最小化
- Cell単位での独立運用により、リージョン障害時もプラットフォーム全体ではなく影響Cellのみをフェイルオーバー
- デプロイメント失敗の影響範囲をCell内に限定し、運用の柔軟性を確保
Operational Readiness Reviews (ORR)
- AWSが運用インシデントから得た学びを、ベストプラクティスガイダンス付きの質問として体系化したフレームワーク
- 目的は「より短く、より少なく、より小さな」インシデントを実現すること
- AWSの分散型運用文化において、開発者の速度と俊敏性を犠牲にせずにベストプラクティスを共有・適用するためのスケーラブルなセルフサービスメカニズムとして設計
- Correction of Errors (COE) による事後分析から得られた知見を、他のワークロードでの予防可能なリスクの発生を防ぐために活用
- ORRの質問はリスクを明らかにし、インシデントの共通原因を排除するためのベストプラクティス実装についてチームを教育
- ワークロードのライフサイクル全体(設計から本番運用後まで)を通じて、適切なORRチェックリストを使用した自己評価を実施
- Well-Architected Frameworkの運用エクセレンスと信頼性の柱を補完し、組織固有のビジネス、文化、ツール、ガバナンスルールに特化した学びを含めることが可能
- データ駆動型アプローチにより、ワークロードにおける既知の一般的な影響原因を排除するための一貫したレビューを実現
Resilience Lifecycle Framework
- AWSが顧客や内部チームとの長年の経験から開発した、レジリエンス向上のための継続的なアプローチを定義するフレームワーク
- 現代の組織は「常時稼働、常時利用可能」という顧客期待の変化に伴い、レジリエンス関連の課題が増大している
- AWSはレジリエンスを「インフラストラクチャ、依存サービス、設定ミス、一時的なネットワーク問題などの障害に対して、アプリケーションが抵抗または回復する能力」と定義
- 5つのステージで構成される継続的なライフサイクル
- 望ましいレジリエンスレベルを達成するには、運用の複雑性、エンジニアリングの複雑性、コストのトレードオフを評価・調整する必要がある
- ソフトウェア開発ライフサイクル(SDLC)と同様のプロセスとしてモデル化されており、アジャイル開発プロセスのように開発の各イテレーションで繰り返し実行可能
- 各ステージの実践を時間をかけて段階的に深化させることを推奨
2 Builder's Library, Blog
静的安定性関連
- アベイラビリティーゾーンを使用した静的安定性
- 分散システムでのフォールバックの回避
- 重大な障害を処理するための戦略
- 再試行: すぐに、または少し遅れて、失敗したアクティビティを再度実行します。
- 積極的な再試行: アクティビティを並行して複数回実行し、最初のアクティビティを使用して終了します。
- フェイルオーバー: エンドポイントの別のコピーに対してアクティビティを再度実行するか、できればアクティビティの複数の並行コピーを実行して、それらの少なくとも 1 つが成功する確率を上げます。
- フォールバック: 異なるメカニズムを使用して、同じ結果を達成します。
- フォールバック戦略の問題点
- テストが困難
- フォールバック自体が失敗する可能性
- システム障害を悪化させる可能性
- 潜在的なバグが存在
- Amazonのフォールバック回避策
- 非フォールバックケースの信頼性向上(メインコードをより堅牢にすることで可用性を高める)
- 発信者にエラー処理を任せる
- データを積極的にプッシュ(E.g. サービスに必要なデータがすでにローカルにある)
- フォールバックをフェイルオーバーに変換
- 再試行とタイムアウトの適切な管理
- 重大な障害を処理するための戦略
耐障害性設計
-
- クラウドにおけるレジリエンスパターン
- レジリエンスパターンの詳細
- 1/マルチAZ
- 単一リージョン内の複数AZを使用
- 低コストだが、バイモーダル動作としてAZダウン時の回復時間が毀損
- 2/静的安定性を持つマルチAZ
- 複数AZに事前にリソースを配置
- コストは高いが、障害時のダウンタイムを最小化
- 3/アプリケーションポートフォリオ分散
- 重要なアプリケーションを複数リージョンに分散
- リージョン障害の影響を軽減するが、運用が複雑
- 4マルチAZ展開(マルチリージョンDR)
- パイロットライトやウォームスタンバイなどのDRパターンを使用
- リージョン障害に対応するが、複雑性が増加
- 5/マルチリージョンアクティブ-アクティブ
- 複数リージョンで同時に稼働
- 最高レベルの可用性を提供するが、最も複雑で高コスト
- 1/マルチAZ
Improving Performance and Reducing Cost Using Availability Zone Affinity | AWS Architecture Blog
- AZアフィニティの概要
- クロスAZの影響
- AZ間のデータ転送は遅延とコストを増加させる。
- 同一AZ内の通信は通常サブミリ秒の遅延だが、AZ間は数ミリ秒の遅延が発生。
- AZアフィニティの実装方法
- ワークロードの耐障害性
- クライアントは単一AZに「固定」されるが、問題発生時には他のAZにフェイルオーバー可能。
- 指数バックオフを伴うリトライや、他のAZへのリクエスト送信で対応。
- クライアントライブラリの活用
- サービスディスカバリ、リトライ、フェイルオーバーを処理するクライアントライブラリの提供が有効。
- ユーザーに低レベルAPIと高レベルライブラリの両方のオプションを提供。
- 結論
- AZアフィニティパターンは、マルチAZシステムの遅延とデータ転送コストを削減しつつ、高可用性を維持。
- すべてのワークロードに適しているわけではないが、特定の要件下では検討に値する。
-
- 段階的デプロイメント戦略
- 自動化による安全なデプロイ
- ロールバック安全性の確保
-
- 障害分離の実装
- 監視とアラートの設計
- 継続的改善のプロセス
実装パターン
- ジッターを伴うタイムアウト、再試行、およびバックオフ
- ヘルスチェックの実装
- ヘルスチェックのトレードオフ
- 重大ではない理由でヘルスチェックが失敗し、その失敗がサーバー間で相関している場合、トラブルが発生
- ヘルスチェックの種類と特徴
- ライブ状態チェック:基本的な接続とプロセスの存在を確認
- ローカルヘルスチェック:アプリケーションの機能を確認
- 依存関係のヘルスチェック:他システムとの対話能力を検査
- 異常検出:フリート内のサーバー間の動作を比較
- ヘルスチェック失敗への対応
- フェールオープン:すべてのサーバーが失敗した場合にトラフィックを許可
- サーキットブレーカーなしのヘルスチェック:LBからはライブ&ローカルヘルスチェック。外部から依存関係のヘルスチェック&異常検出
- ヘルスチェックの実装における注意点
- 正常性を優先する設定
- 過負荷状態ではヘルスチェックのレスポンスを優先するようにする
- 依存関係のヘルスチェックと影響範囲のバランスデプロイ時の複数の緩和システムの実装
- フェールオープン保護がなければ、依存関係をテストするヘルスチェックを実装すると、その依存関係が「ハードな依存関係」に変わります。 依存関係がダウンすると、サービスもダウンし、影響範囲が拡大する連鎖障害が発生します。
- 正常性を優先する設定
- Challenges with distributed systems
- 分散システムの8つの障害モード
- POST REQUEST失敗: ネットワーク配信失敗
- DELIVER REQUEST失敗: サーバー受信直後のクラッシュ
- VALIDATE REQUEST失敗: メッセージ無効判定
- UPDATE SERVER STATE失敗: 状態更新失敗
- POST REPLY失敗: 応答投稿失敗
- DELIVER REPLY失敗: クライアント配信失敗
- VALIDATE REPLY失敗: 応答無効判定
- UPDATE CLIENT STATE失敗: クライアント状態更新失敗
- 分散システムの8つの障害モード
- ヘルスチェックのトレードオフ
監視
- 運用の可視性を高めるために分散システムを装備する
- Amazon では、最初にログを記録し、後から集約メトリックを作成する
- リクエストログのベストプラクティス
- ログ分析ツール
3. re:Inventセッション
ARC335 Designing for failure: Architecting resilient systems on AWS
- 主要テーマ: 障害を前提とした設計
- 重要ポイント:
- "Everything fails all the time"の原則
- RTO/RPOの適切な設定
- 継続的なテストの重要性
Are you ready? Essential Strategies for Kubernetes Adoption
- 主要テーマ: Kubernetesの本番運用戦略
- 重要ポイント:
- Platform as a Serviceの実現
- GitOpsによる一貫した運用
- 段階的な機能導入
-
- はじめに
- Amazon.comの実例を通じて、スケーラブルで耐障害性のあるアーキテクチャについて学ぶ。
- 1995年に2台のサーバーから始まったAmazonが、現在では大規模なインフラストラクチャを運用している。
- 重要ポイント:
- セルベースアーキテクチャの実装
- カオスエンジニアリングの実践
- 観測可能性の向上
- はじめに
4. Application Recovery Controller (ARC)
-
- Zonal Shiftの適切な使用法
- 容量計画の重要性
- 定期的なテストの実施
単一アベイラビリティーゾーンでのアプリケーション障害からの迅速な復旧 | Amazon Web Services ブログ
- ゾーンシフトの概要
- 単一AZアプリケーションの障害に対応するための準備
- パッシブモニタリングとアクティブモニタリングの併用
- パッシブモニタリング - サーバーサイドメトリクス
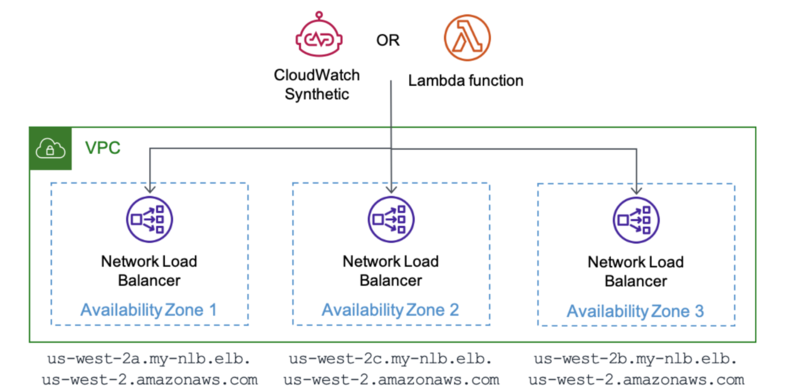
- ALB と NLB の両方が、UnhealthyHostCount や ProcessedBytes などの AZ 単位のメトリックを提供
- アクティブモニタリング - 外形監視
- ALB と NLB の両方が、標準のリージョンの DNS 名に加えて、ゾーン DNS 名を提供します。これにより、以下のように、各ゾーンのアプリケーションレプリカの応答性と信頼性を個別に監視するカナリアを作成することができます
ELB name: zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2A: ap-southeast-2a.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2B: ap-southeast-2b.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2C: ap-southeast-2c.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com- https://dev.classmethod.jp/articles/zoneshift-2az-try/
- ALB と NLB の両方が、標準のリージョンの DNS 名に加えて、ゾーン DNS 名を提供します。これにより、以下のように、各ゾーンのアプリケーションレプリカの応答性と信頼性を個別に監視するカナリアを作成することができます
- パッシブモニタリング - サーバーサイドメトリクス
- パッシブモニタリングとアクティブモニタリングの併用
- ゾーンシフトのベストプラクティス
- ゾーンシフトの試行
re:Invent 2023: AWSが語るAZ障害からの自動回復 - zonal autoshiftの紹介
- AWSにおける障害対応
- Central Incident Response Teamが検知ししシフトさせる
- 検出と対応を一元化することは非常に有用
- ただし、スケーリングについては、依然としてそれらのサービスチームが対応する(シフト/回復時のスケーリング)
- マイクロサービスとAZ回復
- サイロモデル:AZ内でマイクロサービスを完結させる
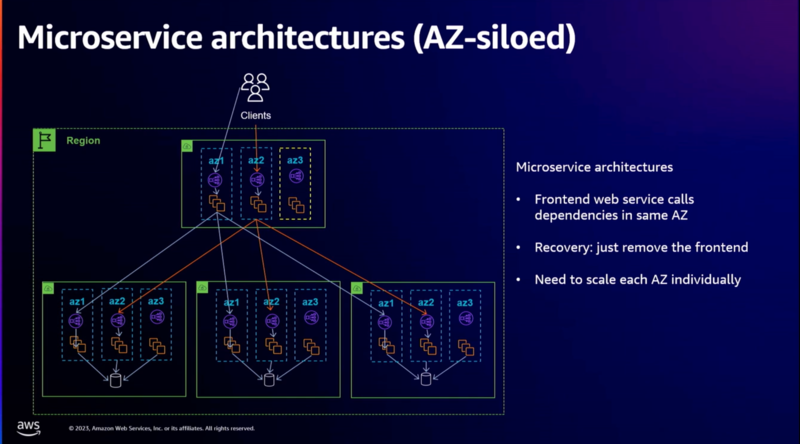
- この素晴らしい点は、AZの障害から回復したい場合、フロントエンドでAZ 3を切り離すだけで、 バックエンドに全く変更を加えることなく、AZ 3のすべてのバックエンドが静かになり始める
- このモデルには一定のポイントまでスケールアップできるものの、その後は少し難しくなるという問題がある(チーム数、サービス数がスケールした際に調整が困難になる)
- 多くのチームが独立して運用でき、お互いの業務に干渉しないことに相反する点(要は管理が難しい)
- 特に、その決定に20〜30のチームが関与している場合はなおさ
- E.g.
- フロントエンドサービスがAZ 4に容量を追加することを決めた場合、他のすべてのマイクロサービスもそれに追随してAZ 4にデプロイしなければならない
- AZごとのデプロイを各サービスが実施した際に、それがずれていれば複数AZに障害がわたる可能性がある
- ※NLBのAvailability Zone DNS affinityで実装しやすくはなった
- 呼び出し元AZを意識したルーティング
- 多くのチームが独立して運用でき、お互いの業務に干渉しないことに相反する点(要は管理が難しい)
- このモデルには一定のポイントまでスケールアップできるものの、その後は少し難しくなるという問題がある(チーム数、サービス数がスケールした際に調整が困難になる)
- サイロモデル:AZ内でマイクロサービスを完結させる
- Decoupledモデル:各サービスがお互いをリージョナルとして呼び出す
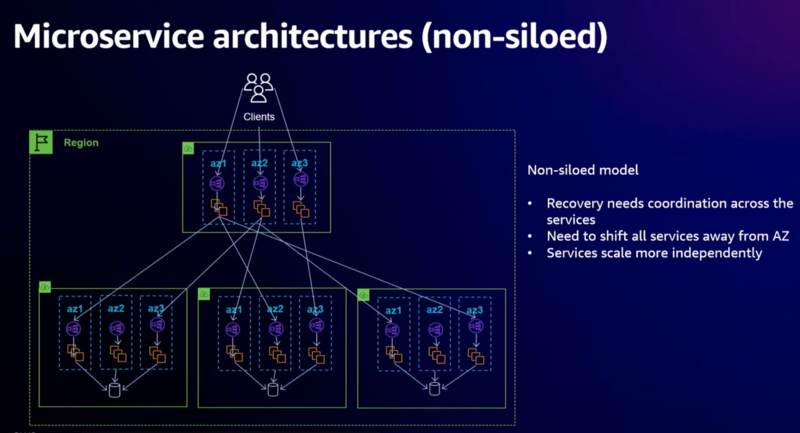
- マイクロサービスそれぞれがAZ 3から独立して回復する必要がある
- Amazonでは、Decoupledモデルの場合、インシデント対応チームがフロントエンドサービスだけでなく、すべてのマイクロサービスも処理できる準備ができていれば、それほど問題にはならない
- Learning
- 1/ AZ Resilient Design
- 2/ グレーの障害を、それが何であるかや解決方法を心配せずにハードな障害に変える
- 単にAZがダウンしていると仮定し、原因を突き止めるまでそこへのトラフィックを止める
- 3/ マネージド、リージョナルサービスを利用する
- 特にデータベース層では、AZ障害に対処できる管理されたリージョナルサービスを好んで使用
- 4/ 事前スケール
- 5/ 理想的には、多くのサービスが関与している場合、中央のチームが検出してシフトを行うことが本当に役立つ
- 6/ 定期的なテストサイクルを設けることが重要
- Zonal Shiftとauto shift
- Zonal Shift:AZからトラフィックを迅速に移動させる機能
- auto shift:AWSが自動的にZonal Shiftを適用する新機能
- AZに潜在的な影響がある場合に実行→十分な容量が必要
- 事前にキャパシティを確保し、定期的な練習が重要
- practice runの契約の一部として、アラームを提供していただき、そのアラームが発生した場合にpractice runを停止
- autoshiftと共にAWS Fault Injection Serviceの新機能もリリース
- 停電テストを導入し、実際にAZでの電源障害をシミュレートして、その対応としてzonal shiftをどのように使用できるかを確認することができます

5. その他参考
- 10 Lessons from 10 Years of Amazon Web Services | All Things Distributed
- 予期せぬ事態への備え:障害は避けられないものとして、システム全体を停止せずに問題に対処できる設計が必要。(managing the “blast radius”)
- AWS re:Invent 2018: How AWS Minimizes the Blast Radius of Failures (ARC338) - YouTube
- AWSの障害対策の基本方針
- 障害の影響範囲(ブラストラディウス)を最小限に抑えることが重要
- 完全に障害を防ぐことは不可能だが、影響を局所化することは可能
- AWSの障害対策の基本方針
- AWS re:Invent 2022 - Camada Zero: A real-world architecture framework (PRT268) - YouTube
- [レポート]Everything fails, all the time:分散システムにおける耐障害性のある設計について #AP-19 #AWSSummit | DevelopersIO
- AWS re:Invent 2022 - Operating highly available Multi-AZ applications (ARC329) - YouTube
- re:Invent 2024: AWSのCloud Resilienceチームが語る多層的な耐障害性
- Resilience Lifecycle Framework
- 顧客事例(Vanguard, United Airlines)