以前、AKS上にIstioのBookinfoサンプルアプリをデプロイして、PrometheusとJaegerによる監視について検証をした。
kashionki38.hatenablog.com
今回は、このアプリに対してJmeterで実際に負荷をかけてみて、どのようにそれぞれのダッシュボード上で負荷を観測できるのかを検証してみた。 ただ負荷をかけるとだけだと面白くないので、ボトルネックを意図的に仕込んでみて、用意した監視ツールでどういうふうに観測できるのか、どうやって真因にたどり着くのか、を検証することにした。
負荷がけと準備
Jmeterシナリオ
今回はJmeterでproductpageにgetリクエストをひたすら投げるシナリオを作成した。
※言わずもがな超々シンプルです。

ボトルネック仕込み
ボトルネックを用意しておかないと面白くないので、reviews-v3のCPU limitsを0.05に引き下げて実施した。
- apiVersion: extensions/v1beta1 kind: Deployment app: reviews version: v3 name: reviews-v3 (中略) spec: template: spec: containers: - image: docker.io/istio/examples-bookinfo-reviews-v3:1.15.0 resources: limits: cpu: 50m requests: cpu: 50m (中略)
監視:サービスメトリクス(RED)
まずは、サービスとしてのSLA系のメトリクスのダッシュボード。Istio導入時のBuilt-inが結構良かったのでそのまま使っている。
Prometheus Istio Mesh Dashboard
サービス全体を見れるIstio Mesh DashboardがそれぞれのサービスについてのSLA値(リクエスト数、レイテンシ、Success Rate)が見れるため、瞬間瞬間のREDを確認しているには適している。

Success Rateが100%未満になったときには緑から色が変わるのでわかりやすくなる。
まずはこのSuccess Rateとレイテンシを見ておくのが重要だと思う。
 この例だと、P90 Latencyを見ると、reviews-v3とproductpage-v1のレイテンシが遅延していることがわかる。
この例だと、P90 Latencyを見ると、reviews-v3とproductpage-v1のレイテンシが遅延していることがわかる。
この値をベースに各性能試験の自動評価は簡易に実装できるなーと思った。
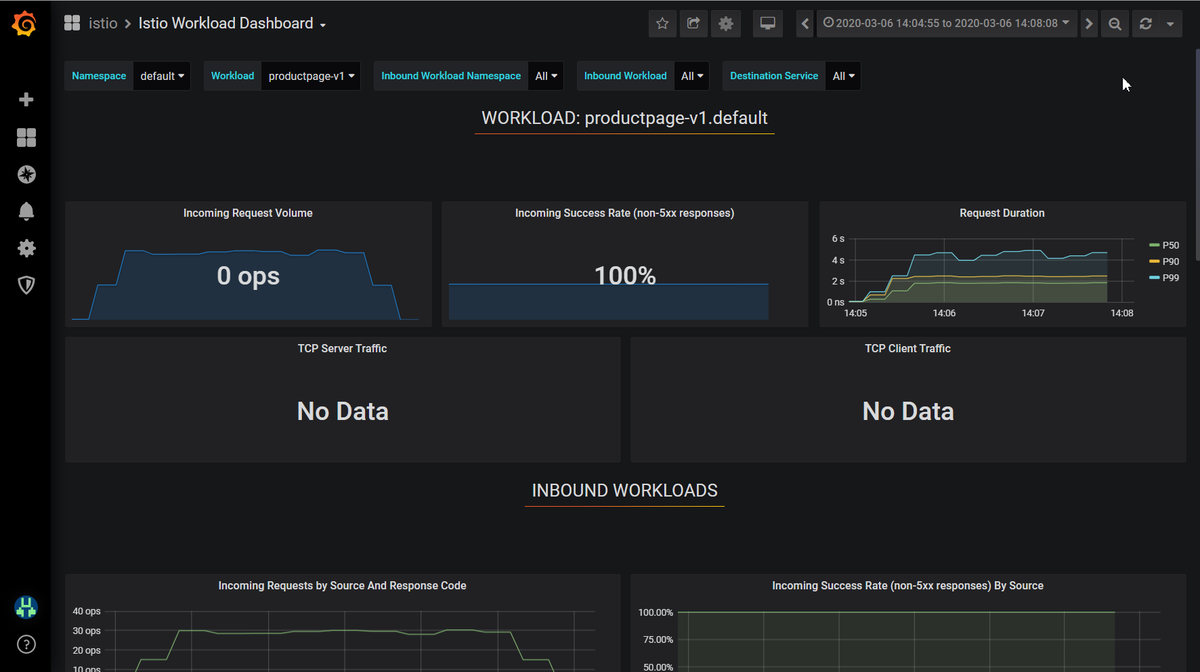
Prometheus Istio Workload Dashboard
Istio Mesh Dashboardで悪い値が出たり、それぞれのサービスに関する時系列値の推移を見たくなったりしたが、Istio Workload Dashboardが便利。
いつから遅延し始めたのか、その際にトラフィックも高かったのか、どういったHTTPエラーがどれくらい返っているのかなど、基本的な情報を把握することができる。

Jaeger
遅延時の追い方は色々あると思うが、今回は折角トレーシングツールとしてJaegerが入っているので、Jaegerでどう表示されるのかを見てみた。
(このために、バックエンドのreview-v3をボトルネックにした笑)
producpageのServiceに絞ると、だいたい2secほどで推移していることがわかる。
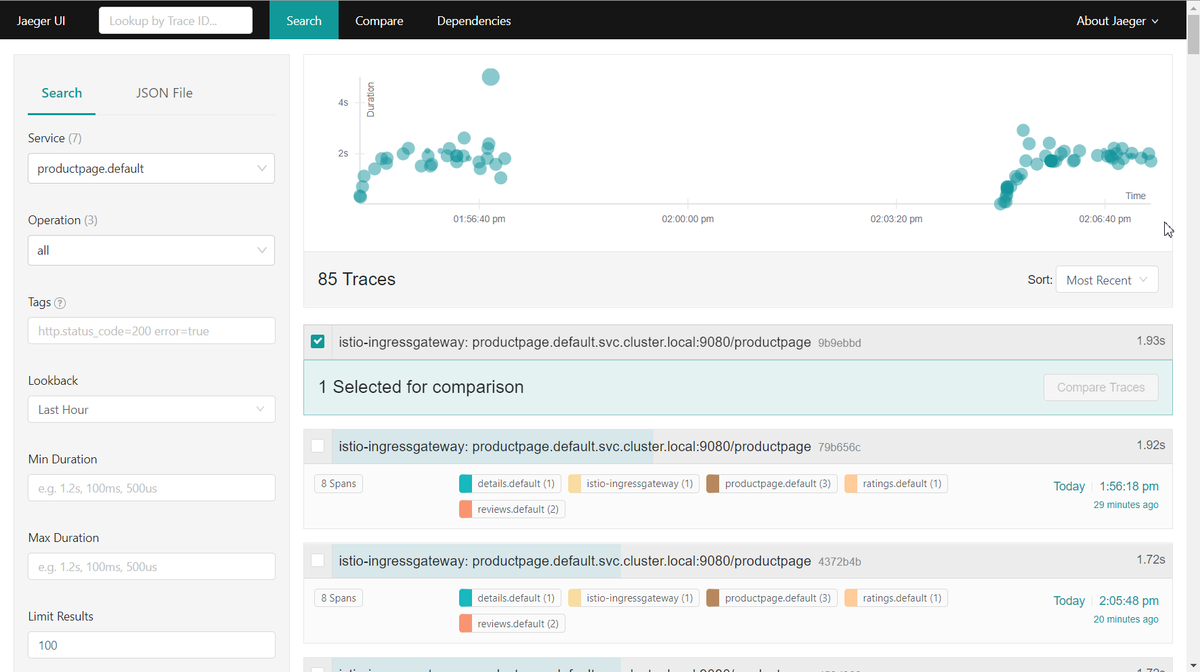
実際にトレースのサンプルを開いてみると、productpageの2secのうち、1.93secはreviewsで費やされていることがわかる。

ちなみに、こんな感じの表示もできる。
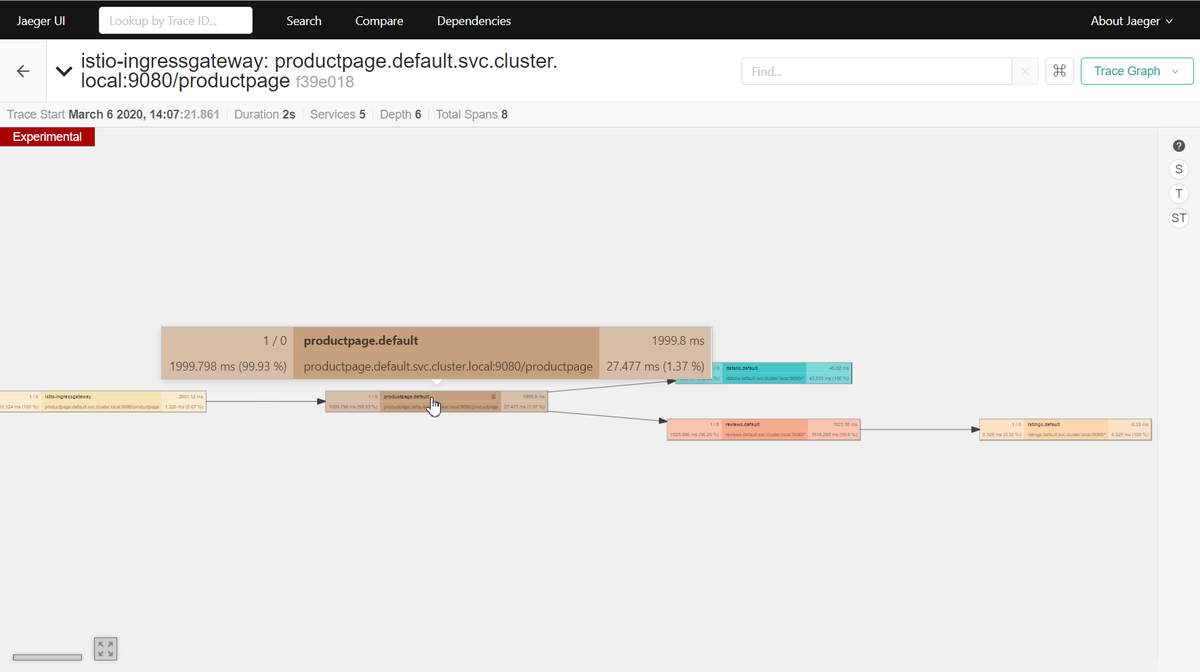

ここまでで、productpageとreviews-v3が遅延しているが、真犯人はreviews-v3であり、productpageはそれを呼んでいるから煽りを食らっているだけという仮説を立てることができるはずだ。
監視:リソースメトリクス(USE)
Prometheus Pod Stats & Info
これは以前の記事で書いたが、別で導入したpod用のダッシュボード。
grafana.com
kashionki38.hatenablog.com
それぞれのpodのリソース使用量、Requests、Limitsが可視化される。
今回だと、reviews-v3がボトルネックっぽいという仮説が立っているのでまずはreviews-v3のpodリソース使用状況を確認するだろう。
すると、こんな感じで見事reviewsコンテナのCPU使用量がLimitsまで張り付いていることがわかる。

これで一見落着、podのlimitsを拡張しよう、というアクションを打つことになるだろう。
Prometheus 1 Node Exporter for Prometheus Dashboard
その前に、Nodeのリソース使用量に(今回だとCPU)に余裕はあるのか確認はしておくべきだろう。
※このダッシュボードも以前の記事で書いた別で導入したダッシュボード。
grafana.com
この通り、NodeのCPU使用率は40%程度と余裕があるので、reviews-v3のLimitsを引き上げるという判断をすることになるだろう。

まとめ
Istioのビルトインのダッシュボードと、Grafanaで公開されているダッシュボードだけで、最低限サービスとpodレベルのUSE×REDな監視はできるということがわかった。
また、Jaegerを使うことで、マイクロサービスの依存関係とそのレイテンシへの影響も可視化できるので複雑であればあるほど必須だろうなと思った。
とはいえ今回はかなーりシンプルなシナリオ+シンプルなアプリだったので、超薄い解析しかしてない。もっと複雑なユースケースとかにDeepDiveしていきたいなーと思った。